오늘은 Azure ML에서 제공하는 비행기 데이터와 날씨 데이터를 통해 비행 지연 여부 또는 정시 운행 여부를 두 가지 클래스로 예측할 것입니다.
비행이 지연된 경우 두 클래스는 1로, 비행 시간이 0이면 0으로 표시됩니다.
Azure ML Studio에서 실험을 빌드하는 데 5 가지 기본 단계가 있습니다.
모델 만들기
모델 훈련
모델 점수 및 테스트
데이터
미국 교통국의 TranStats 데이터 수집에서 얻은 여객 비행 정시 성능 데이터 .
데이터 집합에는 2013 년 4 월 -10 월 기간의 비행 지연 데이터가 포함됩니다. 데이터를 Azure ML Studio에 업로드하기 전에 다음과 같이 데이터를 사전 처리했습니다.
- 미국 대륙에서 70 개의 가장 바쁜 공항 만 포함하도록 필터링되었습니다.
- 취소 된 항공편의 경우 15 분 이상 지연된 것으로 레이블이 재 지정되었습니다.
- 전환 된 항공편을 걸러 냈습니다.
데이터 세트에서 Year , Month , DayofMonth , DayOfWeek , Carrier , OriginAirportID , DestAirportID , CRSDepTime , DepDelay , DepDel15 , CRSArrTime , ArrDelay , ArrDel15 및 Canceled 열을 선택했습니다 .
이 열에는 다음 정보가 포함됩니다.
캐리어 -IATA에서 할당하고 일반적으로 캐리어를 식별하는 데 사용되는 코드입니다.
OriginAirportID- 고유 공항 (비행 출발지)을 식별하기 위해 US DOT에서 할당 한 식별 번호입니다.
DestAirportID- 고유 공항 (비행 목적지)을 식별하기 위해 US DOT에서 할당 한 식별 번호입니다.
CRSDepTime- 현지 시간의 CRS 출발 시간 (hhmm)
DepDelay- 예정된 출발 시간과 실제 출발 시간의 차이 (분)입니다. 조기 출발에는 음수가 표시됩니다.
DepDel15- 출발이 15 분 이상 지연되었는지 여부를 나타내는 부울 값 (1 = 출발 지연)
CRSArrTime-현지 시간 (hhmm)의 CRS 도착 시간
ArrDelay- 예약 된 시간과 실제 도착 시간의 차이 (분)입니다. 일찍 도착하면 음수가 표시됩니다.
ArrDel15- 도착이 15 분 이상 지연되었는지 여부를 나타내는 부울 값 (1 = 도착 지연)
취소됨 - 도착 비행이 취소되었는지 여부를 나타내는 부울 값 (1 = 항공편이 취소됨)
우리는 또한 기상 관측 세트를 사용했다 : NOAA의 시간별 육상 기반 기상 관측 .
날씨 데이터는 2013 년 4 월에서 10 월까지의 기간 동안 공항 기상 관측소의 관측치를 나타냅니다. Azure ML Studio에 업로드하기 전에 다음과 같이 데이터를 처리했습니다.
- 기상 관측소 ID는 해당 공항 ID에 매핑되었습니다.
- 가장 바쁜 70 개의 공항과 관련이없는 기상 관측소가 걸러졌습니다.
- 날짜 : 열은 별도의 컬럼으로 분리 된 연도 , 월 및 일 .
날씨 데이터에서 다음 26 열이 선택되었다 : AirportID , 년 , 월 , 일 , 시간 , 시간대 , SkyCondition , 가시성 , WeatherType , DryBulbFarenheit , DryBulbCelsius , WetBulbFarenheit , WetBulbCelsius , DewPointFarenheit , DewPointCelsius , RelativeHumidity , 풍속 , WindDirection , ValueForWindCharacter을 , 역 압력, PressureTendency , PressureChange , SeaLevelPressure , RecordType , HourlyPrecip , 고도계
공항 코드 데이터 세트
실험에 사용 된 최종 데이터 세트에는 공항 ID 번호, 공항 이름, 도시 및 주 (열 : * airport_id *, city , state , name )를 포함하여 미국 공항마다 하나의 행이 포함 됩니다.
전처리 데이터
데이터 세트는 일반적으로 분석하기 전에 사전 처리가 필요합니다.

비행 데이터 전처리
먼저, 프로젝트 열 모듈을 사용하여 가능한 대상 누수 인 데이터 세트 열에서 제외합니다 : DepDelay , DepDel15 , ArrDelay , Canceled , Year .
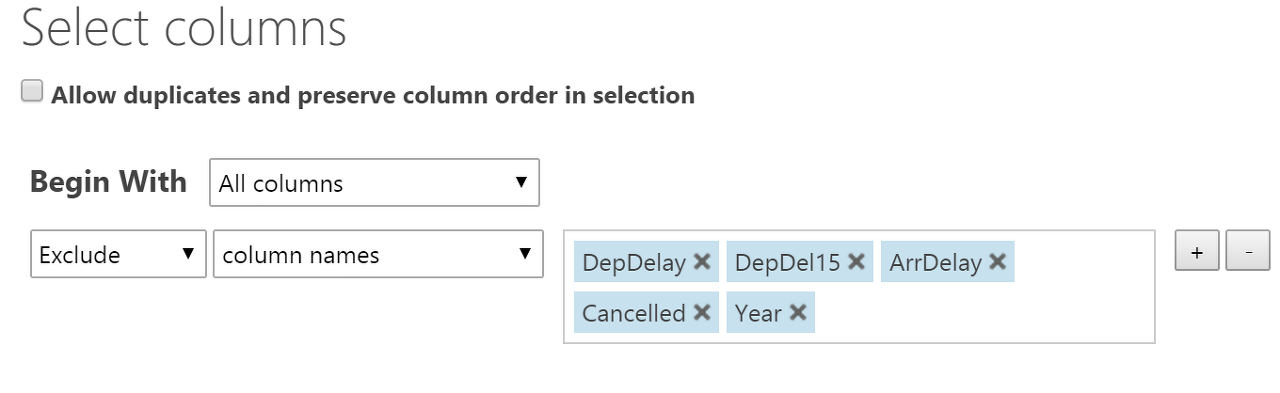
Carrier , OriginAirportID 및 DestAirportID 열 은 범주 속성을 나타냅니다. 그러나 정수이기 때문에 처음에는 연속 숫자로 구문 분석됩니다. 따라서 메타 데이터 편집기 모듈을 사용하여 카테고리로 변환했습니다.

예정된 출발 시간을 조인 키 중 하나로 사용하여 시간별 날씨 기록과 비행 기록을 결합해야합니다. 이렇게하려면 CSRDepTime 열을 수학 연산 적용 모듈 의 연속 된 두 인스턴스를 사용하여 가장 가까운 시간으로 내림해야합니다 .

기상 데이터 전처리
결 측값이 많은 열 은 프로젝트 열 모듈을 사용하여 제외됩니다 . 여기에는 모든 문자열 값 열 ( ValueForWindCharacter , WetBulbFarenheit , WetBulbCelsius , PressureTendency , PressureChange , SeaLevelPressure 및 StationPressure)이 포함 됩니다.

면도 분실 데이터 모듈은 누락 된 데이터 열을 제거하기 위해 나머지 컬럼에 적용된다.
기상 관측 시간은 가장 가까운 전체 시간으로 반올림되므로 열이 예정된 비행 출발 시간과 동일하게 결합 될 수 있습니다. 예정된 비행 시간과 날씨 관측 시간은 반대 방향으로 반올림됩니다. 이는 모형이 비행 시간을 기준으로 과거에 발생한 날씨 관측 만 사용하도록하기 위해 수행됩니다. 날씨 데이터는 현지 시간으로보고되지만 출발지와 목적지는 시간대가 다를 수 있습니다. 따라서 예정된 출발 시간 ( CRSDepTime ) 및 날씨 관측 시간 ( Time ) 에서 시간대 열을 빼서 시간대 차이를 조정해야합니다 . 이 작업은 R 스크립트 실행 모듈을 사용하여 수행됩니다 .
결과 열은 Year , AdjustedMonth , AdjustedDay , AirportID , AdjustedHour , 시간대 , 가시성 , DryBulbFarenheit , DryBulbCelsius , DewPointFarenheit , DewPointCelsius , RelativeHumidity , WindSpeed , Altimeter 입니다.
데이터 세트 가입
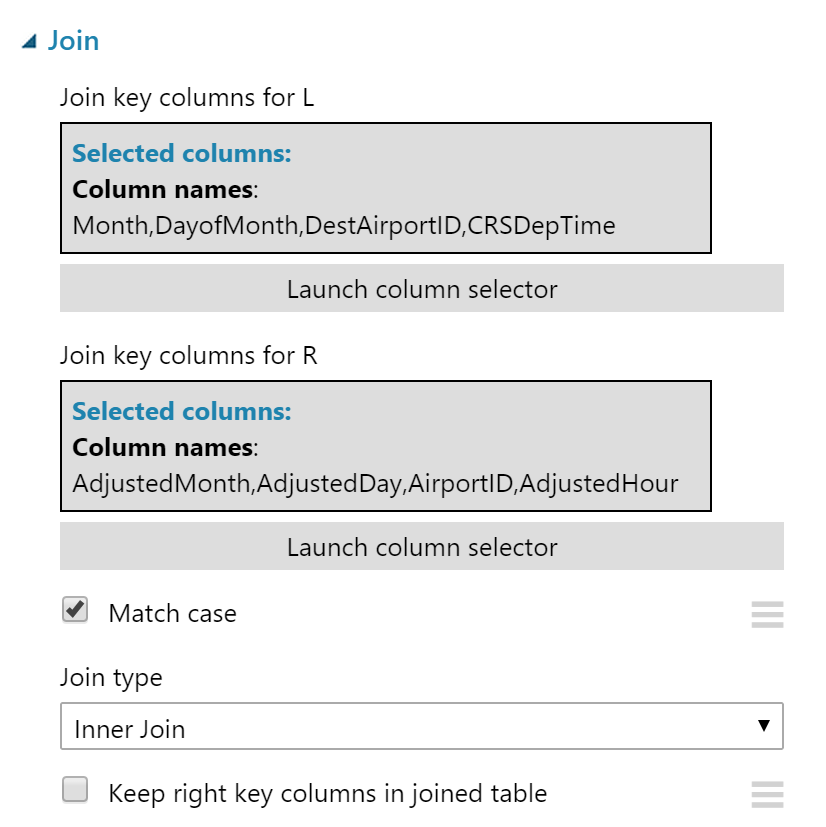
비행 기록은 Join 모듈 을 사용하여 비행 출발지 ( OriginAirportID ) 의 날씨 데이터와 결합됩니다 .

비행 기록은 비행 목적지 ( DestAirportID )를 사용하여 날씨 데이터와 결합됩니다 .
교육 및 검증 샘플 준비
학습 및 유효성 검증 샘플은 데이터를 학습용 4 월 -9 월 레코드와 유효성 검증 용 10 월 레코드로 나누기 위해 Split 모듈을 사용하여 작성됩니다 .

프로젝트 열 모듈을 사용하여 연도 및 월 열이 교육 데이터 세트에서 제거됩니다 . 그런 다음 훈련 데이터를 Quantize Data 모듈을 사용하여 같은 높이의 빈으로 분리 하고 동일한 비닝 방법을 유효성 검사 데이터에 적용했습니다.

훈련 데이터는 훈련 데이터 세트와 선택적 유효성 검사 데이터 세트로 다시 한 번 분할됩니다.

기능 정의
머신 러닝에서 피처 는 관심있는 대상의 개별 측정 가능한 속성입니다. 예측 모델을 생성하기위한 유용한 피처 집합을 찾으려면 당면한 문제에 대한 실험과 지식이 필요합니다. 일부 기능은 다른 기능보다 목표 예측에 더 좋습니다. 또한 일부 피처는 다른 피처와 강한 상관 관계가 있으므로 모델에 새로운 정보를 많이 추가하지 않고 제거 할 수 있습니다. 모델을 구축하기 위해 사용 가능한 모든 기능을 사용하거나 데이터 집합에서 기능의 하위 집합을 선택할 수 있습니다. 일반적으로 다른 기능을 선택한 다음 실험을 다시 실행하여 더 나은 결과를 얻을 수 있는지 확인할 수 있습니다.
다양한 기능은 도착 및 도착 공항의 기상 조건, 출발 및 도착 시간, 항공사, 월요일 및 요일입니다.
학습 알고리즘을 선택하고 적용하십시오.
모델 교육 및 검증
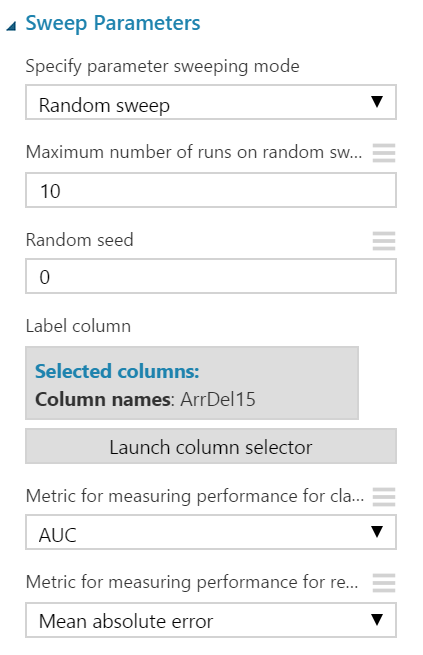
Two-Class Boosted Decision Tree 모듈을 사용하여 모델을 생성 하고 교육 데이터 세트를 사용하여 학습했습니다. 최적의 매개 변수를 결정하기 위해, 우리는의 출력 포트에 연결된 두 클래스 힘 입어 의사 결정 트리를 받는 스윕 매개 변수 모듈.

이 모델은 10 배의 랜덤 파라미터 스위프를 사용하여 최상의 AUC에 최적화되어 있습니다.
비교를 위해 2 클래스 로지스틱 회귀 분석 모듈을 사용하여 모델을 작성 하고 동일한 방식으로 최적화했습니다.
실험 결과는 예측을 위해 새로운 샘플을 채점하는 데 사용할 수있는 훈련 된 분류 모델입니다. 검증 세트를 사용하여 훈련 된 모델에서 점수를 생성 한 다음 모델 평가 모듈을 사용하여 모델 의 품질을 분석하고 비교했습니다.
새로운 데이터를 사용하여 예측
이제 모델을 학습 했으므로이 모델을 사용하여 데이터의 다른 부분 (검증을 위해 따로 설정 한 지난 달 (10 월) 레코드)에 점수를 매기고 모델이 새 데이터를 얼마나 잘 예측하고 분류하는지 확인할 수 있습니다.
스코어 모델 모듈을 실험 캔버스에 추가하고 왼쪽 입력 포트를 기차 모델 모듈 의 출력에 연결하십시오 . 올바른 입력 포트를 Split 모듈 의 유효성 검사 데이터 (오른쪽 포트)에 연결하십시오 .
실험을 실행 한 후 출력 포트를 클릭하고 시각화를 선택하여 점수 모델 모듈 의 출력을 볼 수 있습니다 . 출력에는 점수가 매겨진 레이블과 레이블의 확률이 포함됩니다.
마지막으로 결과의 품질을 테스트하려면 모델 평가 모듈을 실험 캔버스에 추가 하고 왼쪽 입력 포트를 점수 모델 모듈 의 출력에 연결하십시오 . 모듈을 사용하여 두 모델을 비교할 수 있으므로 모델 평가에 대한 두 개의 입력 포트 가 있습니다. 이 실험에서는 두 가지 다른 알고리즘의 성능을 비교합니다. 하나는 2 클래스 부스트 결정 트리를 사용하여 생성 된 것과 2 클래스 로지스틱 회귀를 사용하여 생성 된 것 입니다. 출력 포트를 클릭하고 시각화를 선택 하여 실험을 실행하고 모델 평가 모듈 의 출력을 보십시오 .
결과
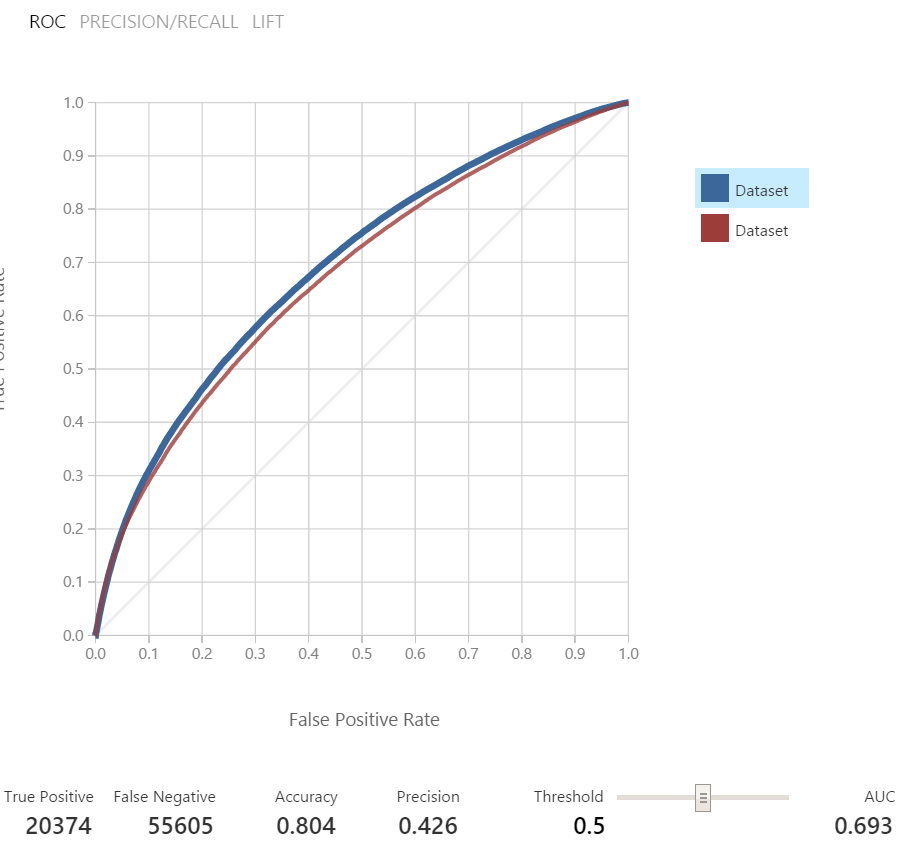
승격 된 의사 결정 트리 모델의 유효성 검사 세트에서 AUC는 0.697이며 로지스틱 회귀 모델보다 AUC는 0.675입니다.
후 처리
결과를보다 쉽게 분석 할 수 있도록 airportID 필드를 사용 하여 공항 이름과 위치가 포함 된 데이터 집합에 참여했습니다.
'Microsoft > Azure ML' 카테고리의 다른 글
| Azure ml로 OH MY GIRL(오마이걸) _ Nonstop(살짝 설렜어)시계열로 조회수 예측!! 3000만은 언제 오는가....!!!!! 옴망진창 (0) | 2020.06.04 |
|---|---|
| Azure ML Module List !!! Apply Filter (필터 적용) (0) | 2020.04.14 |
| Azure ML Module List !!! - Add Rows 활용하는 방법 (0) | 2020.04.13 |
| Azure ML Module List !!! A부터 Z까지 - Add Columns (0) | 2020.04.13 |
| Azure ML One-Class Support Vector Machine 으로 빠르고 간단하게 이상징후 탐지하는 방법 (0) | 2020.03.03 |


