안녕하세요
Azure Machine Learning Studio 처음 사용한다면 할 수 있는 가장먼저 실험해 볼 수 있는 예시를 알려드릴께요!!!
그전에 먼저 튜토리얼을 따라 해볼껀데요!!!

저 버튼을 누르면 알아서 실행되어 쉽게 할 수 있습니다!!
시작하게 되면 먼저 제목을 적게 됩니다. 제목을 적지안으면 나중에 실행을 할 때 오류가 생길 수 있으니
귀찮더라도 꼭 제목을 꼭 써주세요!!
그리고 나서 샘플 창에가면
Adult Census Income Binary Classification dataset (성인 인구 조사 소득 이진 분류 데이터 세트)
샘플을 끌어 당기라고 합니다.

우클릭 후 Visualize(시각화)를 누르게 되면 데이터의 모든 행과 열의 내용들을 확인 할 수 있습니다.

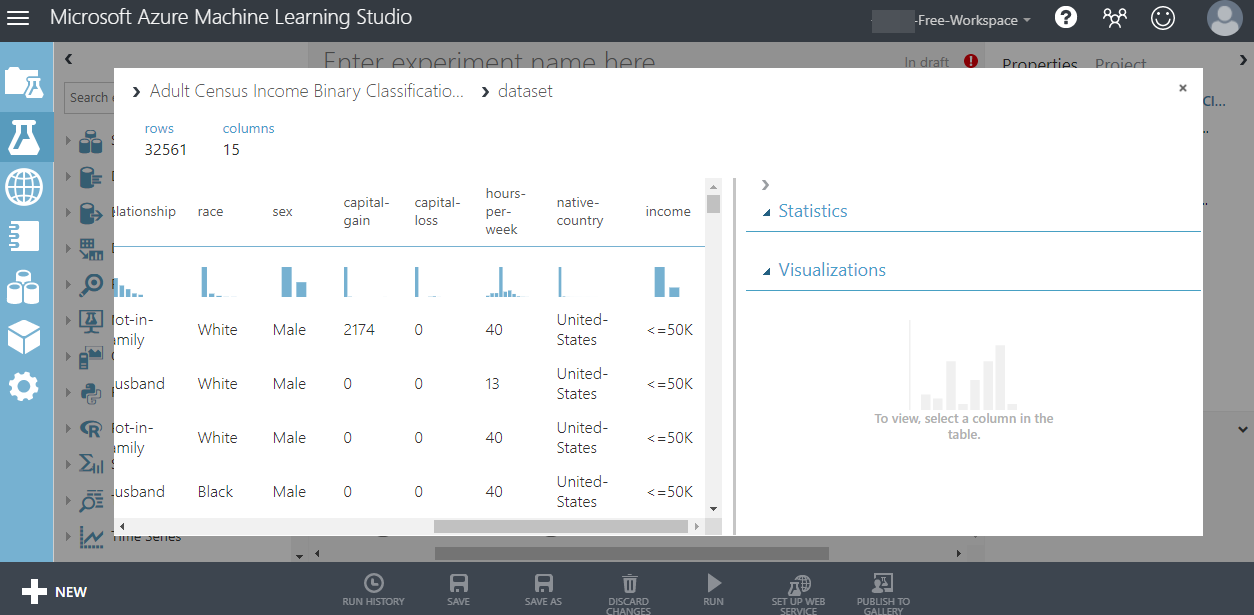
그 다음은 과적합을 방지하기 위해 데이터를 split(쪼개기) 합니다.
과적합이란?
학습 데이터를 과하게 학습(overfitting)하는 것을 뜻합니다. 일반적으로 학습 데이터는 실제 데이터의 부분 집합이므로 학습데이터에 대해서는 오차가 감소하지만 실제 데이터에 대해서는 오차가 증가하게 됩니다.
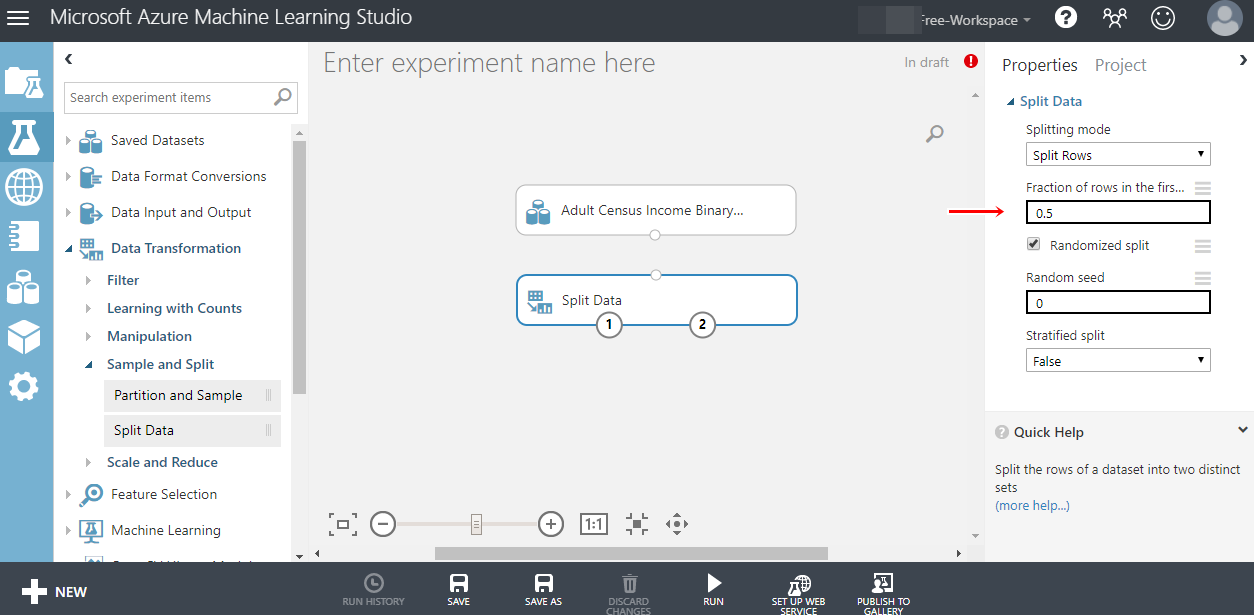
오른쪽에 첫 번째 출력 데이터 세트의 행 비율 0.7로 바꾸시면 7대3의 비율이됩니다.

이제 데이터를 분활 했으니 학습시킬 알고리즘을 선택합니다.
income 속성에 <=50K , >50K 두가지 값 중 하나의 예측값이 나오는 형태이기 때문에
Two-Class Boosted Decision Tree (2 클래스 부스트 결정 트리)를 사용합니다.
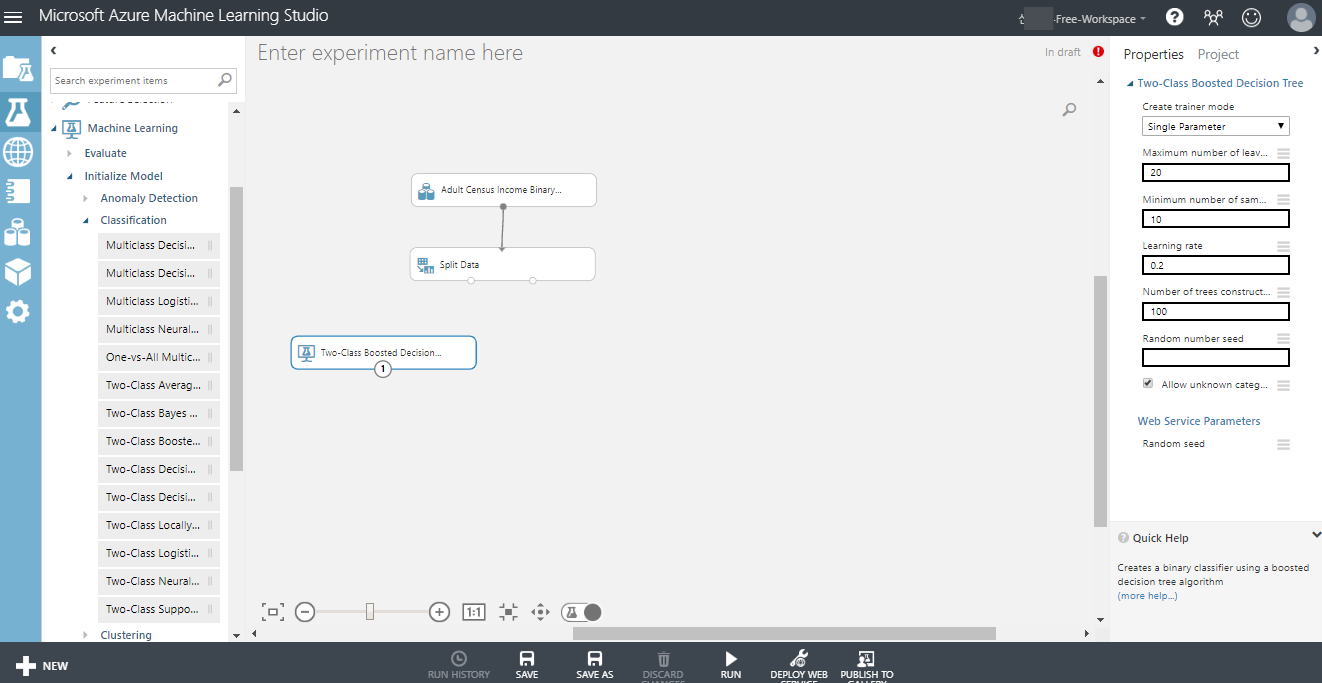

블럭들을 연결을 하고 Train Model에 있는 열선택 창에 들어가 income 속성을 선택합니다.



이렇게 4블럭만 있어도 벌써 완성입니다...!!!
물론...예측값을 평가하여 이게 진짜 좋은 자료가 될지 엉망인 빅데이터 자료가 될지를 판단해야 합니다.


스코어 모델과 평가 모델을 추가하고 아래 플레이버튼(Run)을 클릭하시면 이제 빅데이터 분석을 하게됩니다.

플레이버튼(Run) 클릭후 트레인 모델을 시각화 하면 이 처럼 각 트리들이
어떻게 진행되었는지 확인도 할 수 있습니다.

스코어 모델을 시각화 하시면 위에 캡쳐화면처럼 이 데이터는 income 속성이 <=50K , >50K 두개 중 '00' 이거일 꺼야 라고 예측해줍니다.... 또한 자신의 예측이 맞을 확률도 보여줍니다.

그리고 평가모델을 시각화 할경우 이와같이 ROC곡선 그래프를 확인할 수 있다.
면적이 클수록 좋은 성능을 보인다고 할 수 있다.

아래는 Evaluate Model을 통해 다음과 같은 통계치를 확인 할 수 있다.
True Positive : Positive으로 예측했고, (맞춤!!True) 데이터가 Positive인 경우
False Negative : Negative으로 예측했고, (틀림False) 데이터가 Positive인 경우
False Positive : Positive으로 예측했고, (틀림False) 데이터가 Negative인 경우
True Negative : Negative으로 예측했고 (맞춤True) 데이터가 Negative인 경우
Accuracy
정확도 (예측값이 정답과 얼마나 같은가)
Precision
정밀도 (예측한 값 중에 진짜 예측한 값은 얼마나 있는가)
Recall
재현율 (전체 참 값 중 내가 맞춘 참값의 비율)
이제 웹서비스를 만들어 볼껀데요

아래 Predictive webservice [Recommended]를 클릭하면 바로 자동으로 구축이 할 수가 있습니다.




웹서비스를 좀 더 말끔하게 만들기 위해 select columms in dataset블록을 통해 속성을 제한 할껀데요
저희는 income을 통해 예측하는 서비스를 만들꺼기 때문에 입력값에 있는 income속성을 제외하고


출력값에서는 Scored labels 와 Scored Probabilities를 나오도록 속성값을 정의합니다.
그리고 런(play)후에 deploy 웹서비스를 누르게 되면 아래와 값이 나옵니다.

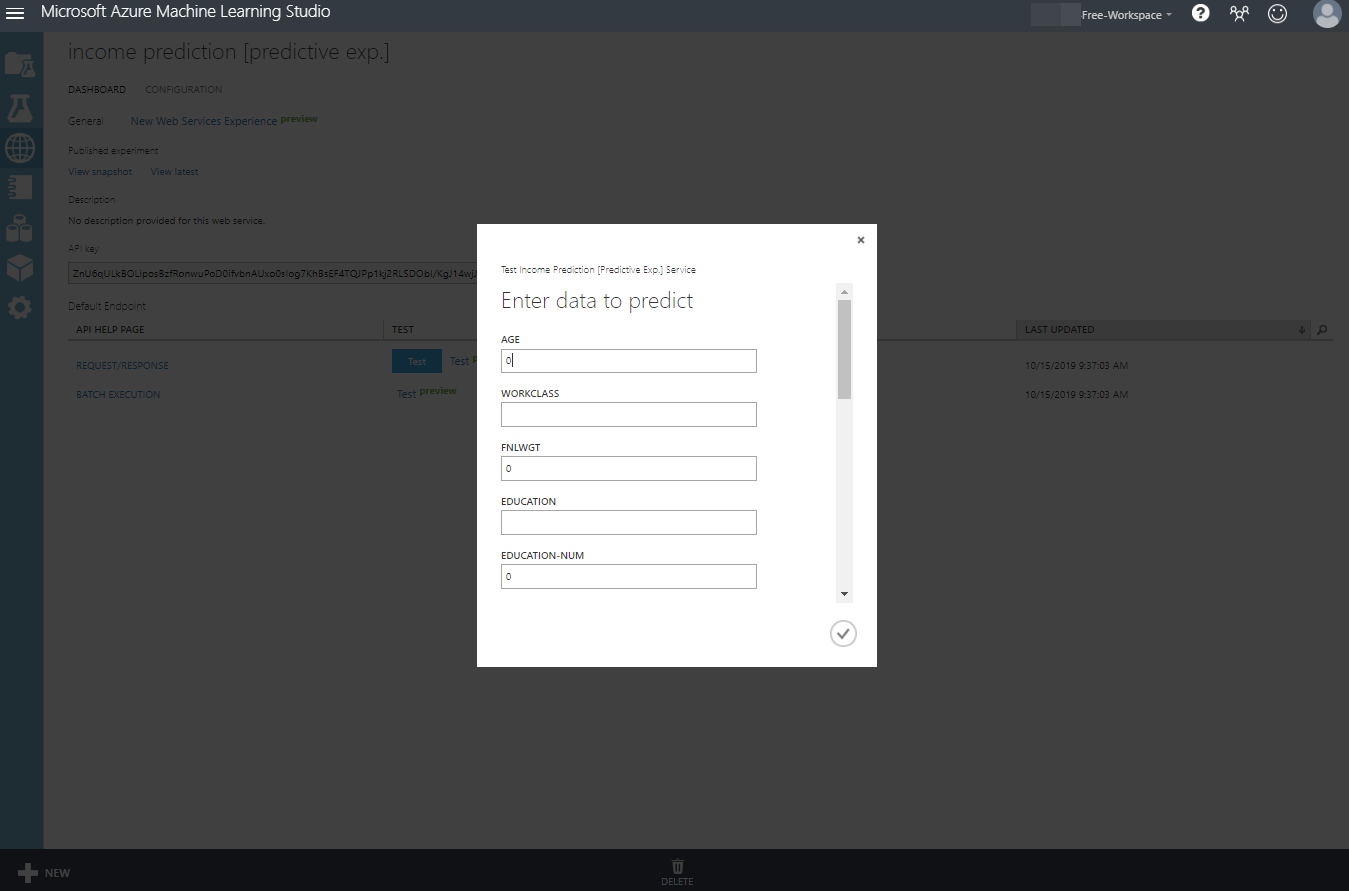
여기서 테스를 눌러 예측모델을 사용 할 수도 있고

프리뷰 버튼을 눌러 쌤플데이터를 통해 웹서비스를 확인 할 수도 있습니다.


테스트를 해보면 각각의 속성을 집어 넣고 이 사람의 소득이 얼마일지
또 그 확률은 얼마일지를 예측할 수 있게 됩니다.!!
'Microsoft > Azure ML' 카테고리의 다른 글
| Azure ML Module List !!! A부터 Z까지 - Add Columns (0) | 2020.04.13 |
|---|---|
| Azure ML One-Class Support Vector Machine 으로 빠르고 간단하게 이상징후 탐지하는 방법 (0) | 2020.03.03 |
| Azure ML 교차검증 Cross Validate Model 사용하기!!! (0) | 2020.02.06 |
| Azure ML 누락된 데이터 정리 Clean Missing Data 사용법 (0) | 2020.01.28 |
| Azure ML Train Matchbox Recommender 추천 알고리즘 (0) | 2019.11.18 |



