회귀 분석: 수요 추정
이 실험은 UCI자전거 대여 데이터에 대한 회귀 분석을 이용한 수요 예측을 보여 준다.
회귀 분석: 수요 추정
이 실험은 자전거 대여 수요 예측을 예로 들어 회귀 모형을 만드는 기능 공학 과정을 보여 준다. 우리는 효과적인 형상 공학이 더 정확한 모델로 이어질 것임을 증명한다.
데이터
자전거 대여 UCI데이터 세트는 이 실험을 위한 입력 원시 데이터로 사용된다. 이 데이터 세트는 미국 워싱턴 DC에서 자전거 대여 네트워크를 운영하는 CapitalBikeshare회사의 실제 데이터를 기반으로 합니다.
데이터 세트에는 17,379개의 열과 17개의 열이 포함되어 있으며, 각 열은 2011년 또는 2012년의 특정 시간 내에 자전거를 렌트한 횟수를 나타냅니다. 이 원시 피쳐 세트에는 날씨 조건(온도, 습도, 풍속 등)이 포함되어 있으며 날짜는 휴일과 평일 등으로 분류되었습니다.
예측할 수 있는 필드는 "cnt"로, 1-977 범위의 카운트 값을 포함하며, 특정 시간 내에 자전거를 렌트할 수 있는 횟수를 나타냅니다.
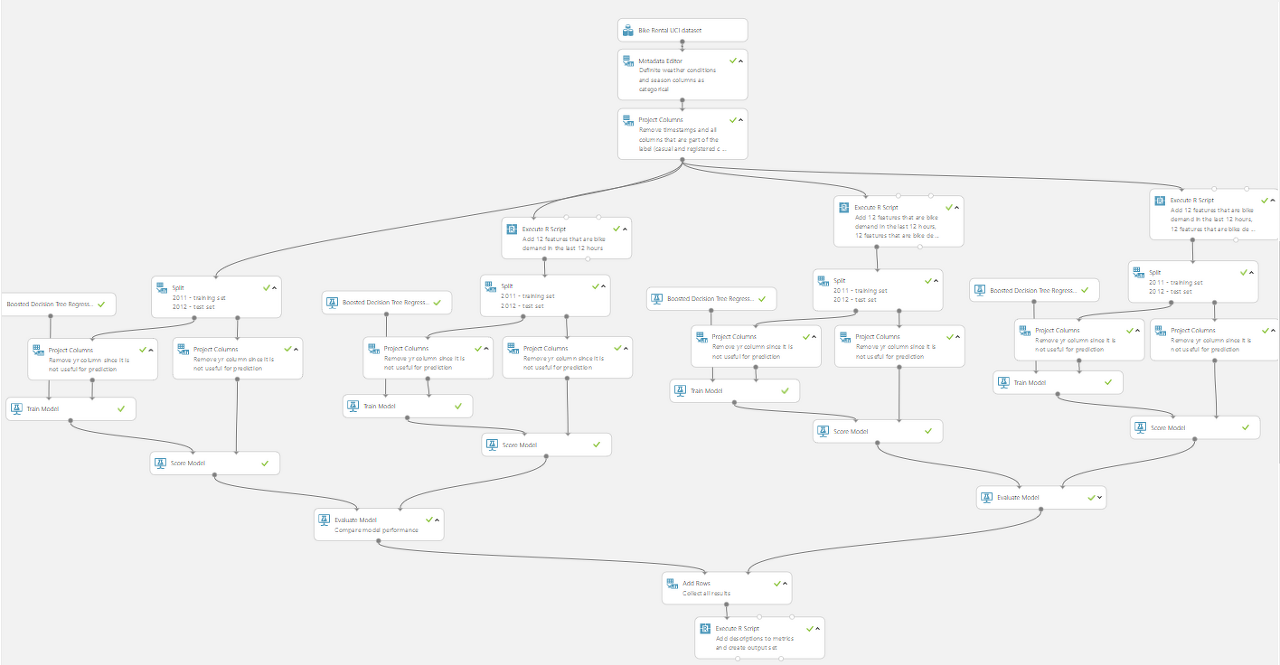
피쳐 공학
교육 데이터에서 효과적인 기능을 구축하는 것이 목표였기 때문에, 우리는 동일한 알고리즘을 사용하지만 4개의 서로 다른 교육 데이터 셋을 사용하여 4개의 모델을 구축했습니다.
입력 데이터는 훈련 데이터가 2011년 기록을 포함하고 시험 데이터는 2012년 기록을 포함하는 방식으로 분할되었다.
구성한 4개의 교육 데이터 세트는 모두 동일한 원시 입력 데이터를 기반으로 했지만 각 교육 세트에 다른 추가 기능을 추가했습니다.
- A=날씨+휴일+평일+예측된 날짜의 주말 기능 설정
- 설정 B=이전 12시간 동안 대여한 자전거의 수
- 설정 C=동일한 시간에 이전 12일 동안 대여한 자전거의 수
- 설정 D=동일한 시간 및 당일에 이전 12주 동안 대여한 자전거의 수
이러한 각 기능 세트는 문제의 다양한 측면을 캡처합니다.
- 기능 세트 B는 자전거에 대한 매우 최근의 수요를 포착합니다.
- 기능 세트 C는 특정 시간에 자전거에 대한 수요를 파악합니다.
- 기능 세트 D는 특정 시간과 요일에 자전거에 대한 수요를 포착합니다.
4개의 교육 데이터 세트는 다음과 같이 기능 세트를 결합하여 구축되었습니다.
- 교육 세트 1:기능 세트 A만
- 교육 세트 2:피쳐 세트 A+B
- 교육 세트 3:기능 세트 A+B+C
- 교육 세트 4:기능 세트 A+B+C+ D
모델
레이블 열(임대 횟수)에는 연속된 실제 숫자가 포함되기 때문에 회귀 모형을 사용했습니다.
특징의 수가 상대적으로 적고(100미만) 이러한 특징이 드물지 않다는 점을 고려하면, 의사 결정 경계는 비선형일 가능성이 매우 높다. 이러한 관찰에 기초하여 실험에 결합된 의사 결정 트리 회귀 알고리즘을 사용하기로 결정했다.
실험 실행
전체적으로, 이 실험은 다섯가지 주요 단계로 이루어졌다.
- 1단계:데이터 가져오기
- 2단계:데이터 사전 처리
- 3단계:기능 엔지니어링
- 4단계:모델 교육
- 5단계:모델을 테스트, 평가 및 비교
1단계:데이터 가져오기
입력 데이터가 저장되는 위치에 따라 AzureML실험에 데이터를 로드하는 여러가지 방법이 있습니다. 로컬 파일 시스템 또는 Reader모듈에서 데이터를 로드할 수 있으며, 이 모듈은 AzureSQL데이터베이스, Hive, 웹 URL등의 다른 여러 영구 스토리지 위치에서 데이터에 액세스 할 수 있습니다.
하지만 UCI자전거 대여 데이터 세트는 이미 AzureMLStudio에서 저장된 데이터 세트로 사용할 수 있으므로, 데이터 세트 목록에서 실험 캔버스로 간단히 드래그 할 수 있습니다.


2단계:데이터 사전 처리
데이터 사전 처리는 대부분의 실제 분석 애플리케이션에서 중요한 단계입니다. 주요 작업으로는 데이터 정리, 데이터 통합, 데이터 변환, 데이터 감소 및 데이터 비차별화와 양자화가 있습니다.
AzureMLStudio에서 데이터 변환 그룹의 이러한 많은 데이터 처리 작업을 지원하는 도구를 찾을 수 있습니다. 예를 들면 다음과 같다.
-
여러 데이터 세트를 결합해야 하는 경우 조인, 행 추가 또는 열 추가 모듈을 사용할 수 있습니다.
-
데이터를 정리하고 변환하려면 모듈을 사용할 수 있습니다. 누락된 데이터 치료, 데이터, 파티션 및 샘플 표준화 또는 데이터 Quantize
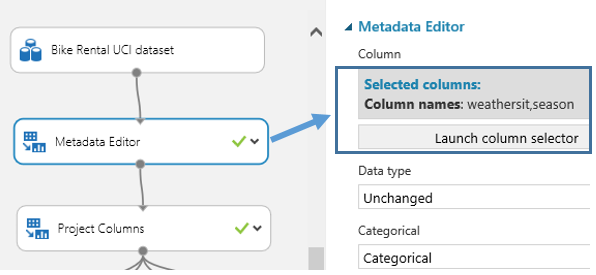
이 실험에서는 메타 데이터 편집기와 프로젝트 열을 사용하여 두 숫자 열"날씨"와 "계절"을 범주형 변수로 변환하고 관련성이 덜한 열("즉시","dt데이","임시","등록")을 제거했습니다.

3단계:기능 엔지니어링
일반적으로 교육 데이터를 준비할 때는 다음 두가지 요구 사항에 주의해야 합니다.
- 먼저 올바른 데이터를 찾아 모든 관련 기능을 통합하고 필요한 경우 데이터 크기를 줄이십시오.
- 둘째, 데이터에서 패턴의 특징을 나타내는 특징을 확인하고, 없는 경우 이를 구성합니다.
피쳐 세트에 많은 원시 데이터 필드를 포함하는 것이 매력적일 수 있지만 더 나은 예측 능력을 제공하기 위해 원시 데이터에서 추가 피쳐를 작성해야 하는 경우가 많습니다. 이를 형상 공학이라고 한다.
이 실험에서는 프로젝트 열에서 생성된 데이터 세트의 복사본 4개를 만들고 R스크립트 실행 모듈을 사용하여 서로 다른 파생 기능 세트를 구성하고 각 데이터 세트에 새 기능을 추가했습니다.
다음 그림은 이러한 분기 중 하나에 포함된 R스크립트를 보여 줍니다.

4단계:모델 교육
다음으로 데이터 분석에 사용할 알고리즘을 선택해야 했습니다. 정확도, 알 수 없음 및 효율성에 따라 각 과제에 적합한 서로 다른 알고리즘을 사용하는 기계 학습 문제(분류, 클러스터링, 회귀, 권장 사항 등)가 많이 있다.
이 실험의 목적은 숫자를 예측하는 것이었기 때문에 회귀 모형을 선택했습니다. 더욱이 특징의 수가 상대적으로 적고(100개 미만) 이러한 특징이 희박하지 않기 때문에 의사 결정 경계는 비선형일 가능성이 매우 높다.
이러한 요인을 기반으로, 일반적으로 사용되는 비선형 알고리즘인 의사 결정 트리 회귀 모듈을 사용하여 모형을 작성했습니다. 우리는 서로 다른 알고리즘을 비교하는 것에 관심이 없었다. 그래서 우리는 네가지 모델을 모두 훈련시키기 위해 같은 모듈을 사용했다.
증가된 의사 결정 트리 회귀 모듈에서 많은 파라미터를 변경할 수 있지만, 이 실험에서는 파라미터를 변경하지 않고 기본 값만 사용했습니다. 모델에 가장 적합한 매개 변수를 찾으려면 스위프 매개 변수 모듈을 사용하는 것이 좋습니다.

분할 모듈을 사용하여 교육 데이터가 2011년 데이터에 기반을 두고 테스트 데이터가 2012년 데이터에 기반을 두도록 입력 데이터를 분할했습니다.(데이터 세트에서, 0이 2011을 의미하고 1이 2012를 의미하는 "연도"열을 참조하십시오.)

5단계:모델을 테스트, 평가 및 비교
모델을 교육한 후 점수 모델 및 평가 모델 모듈을 사용했습니다.
- 점수 모델은 테스트 데이터 집합에 대해 교육된 분류 또는 회귀 모형을 채점합니다. 즉, 모듈은 교육된 모델을 사용하여 예측을 생성합니다.
- 평가 모델은 점수가 매겨진 데이터 세트를 가져와 이를 사용하여 몇가지 평가 메트릭을 생성합니다. 그런 다음 평가 메트릭을 시각화할 수 있습니다.

네가지 모델의 성능을 이해하려면 다음 표의 비교 결과를 참조하십시오.
- 가장 좋은 결과는 특징 A+B+C와 A+B+C+D를 조합한 것이다.
- 기능 세트 D는 A+B+C에 비해 추가적인 개선을 제공하지 않습니다.
